windows 시스템 실행파일의 구조와 원리 책 내용을 요약 및 정리 하는 포스팅이에요.
섹션들의 정보들의 위치와 크기를 나타내는 IMAGE_SECTION_HEADER에 대한 내용을 알아볼 거에요.
IMAGE_SECTION_HEADER의 시작
IMAGE_NT_HEADER에 대한 설명이 이제 다 끝났어요. 그 다음으로 이어질 구조체인 IMAGE_SECTION_HEADER에 대한 설명을 시작할게요.
여기에서도 섹션들의 정보들의 위치와 크기등 여러가지를 알려주는 IMAGE_SECTION_HEADER에 대해 알아볼 건데요. 섹션들의 정보들의 위차와 크기를 나타내는 IMAGE_DATA_DIRECTORY 구조체와 어떤 차이가 있는 걸까요?
IMAGE_DATA_DIRECTORY 구조체에 있는 섹션들은 IMAGE_SECTION_HEADER 구조체에 있는 섹션들에게 병합되어 있기 때문에 PE 파일 내에 정보가 없어요! 따라서 IMAGE_DATA_DIRECTORY 구조체에 있는 섹션들의 정보를 확인하고 싶으면, IMAGE_SECTION_HEADER 구조체에 있는 정보들과 조합해서 찾아야 합니다!
자 진짜로 IMAGE_SECTION_HEADER에 대한 설명을 시작할게요!
IMAGE_SECTION_HEADER 구조체는 40바이트로 구성되어 있고요. IMAGE_FILE_HEADER의 NumberOfSections 필드에 있는 섹션의 개수만큼 IMAGE_SECTION_HEADER 가 존재해요.
이 구조체도 마찬가지로 “WinNT.h” 헤더 파일에 정의되어 있습니다.
1 | #defome IMAGE_SECTION_HEADER 8 |
첫 번째 멤버, BYTE Name[IMAGE_SIZEOF_SHORT_NAME]
섹션의 아스키 이름을 나타내요. IMAGE_SIZEOF_SHORT_NAME은 8바이트로 매크로 상수로 정의되어 있고요. 문자열임에도 불구하고 NULL을 신경쓰지 않아요.
그 이유가 섹션 이름을 8바이트 이상으로 지정했을 경우 링커가 알아서 8바이트 이후의 문자열은 잘라 버린 후 값을 채우기 때문이에요.
두 번째 멤버, DOWRD PhysicalAddress or VirtualSize
이 필드는 OBJ 파일인 경우와 PE의 경우 의미가 달라져요.
PE의 경우 공용체의 VirtualSize 필드를 사용하여 코드와 데이터의 실제 바이트수를 담고 있어요. 즉, 파일 바이트 정렬의 배수로 라운드업이 되기 전의 실제 바이트 수를 담고 있어요.
이 값에 대한 라운드업된 값은 이 구조체의 SizeOfRawData 필드에 저장되요.
이전까지는 OBJ 파일의 경우 공용체의 PhysicalAddress 필드를 통해 섹션의 물리적인 번지를 지정했지만, 현재에는 OBJ의 경우 이 필드는 0으로 세팅되요. 즉, PhysicalAddress 필드는 더 이상 의미가 없어졌어요.
이렇게 물리적인 번지를 직접 사용하지 않는 이유가 현대에는 보호모드가 보편적으로 사용되기 때문이에요.
세 번째 멤버, DWORD VirtualAddress
PE에서 해당 섹션을 매핑시켜야 할 가상 주소 공간 상의 RVA를 가지고 있어요.
즉, 메모리 상에서의 본 섹션의 시작 주소를 의미하는 거죠.
그리고 SectionAlignment 필드 값의 배수가 되어야 한다.
네 번째 멤버, DWORD SizeOfRawData
VirtualSize 필드 값에 대한 파일 정렬(Alignment) 값의 배수로 라운드업된 값이다.
만약 IMAGE_OPTIONAL_HEADER의 FileAlignment 필드의 값이 0x200 이고, VirtualSize 필드 값이 0x35A이면 SizeOfRawData 필드 값은 0x400이 된다.
OBJ 파일의 경우 이 값은 0이다.
다섯 번째 멤버, DWORD PointerToRawData
해당 섹션의 PE 파일 내에서 시작하는 실제 파일 오프셋 값이다.
이 값 역시 IMAGE_OPTIONAL_HEADER의 FileAlignmnet 필드 값의 배수가 되어야 한다.
이 필드의 값은 VirtualAddress 필드의 값과 같을 수도 있고 다를 수도 있다.
그렇게 하는 이유가 VirtualAddress 필드는 IMAGE_OPTIONAL_HEADER의 SectionAlignment 필드 값의 배수가 되기 때문에 바이트 정렬 문제로 인하여 하드디스크 상의 공간을 낭비될 수 있고, 이때 PointerToRawData 필드에 실제 섹션의 파일 상의 시작 오프셋을 지정하고 오프셋에 섹션 데이터를 기록함으로써 PE 파일의 크기를 줄일 수 있는 거라고 해요.
따라서 VirtualAddress 필드와 PointerToRawData 필드 사이의 관계를 파악하는 것이 중요하다고 해요.
VirtualAddress의 값은 RVA이기 때문에 IMAGE_OPTIONAL_HEADER의 ImageBase 필드 값을 더한 결과가 프로그램 로더가 PE 파일을 위하여 프로세스 커널 객체를 생성한 후 가상 주소 공간을 만들고 나서 이 섹션을 해당 주소 공간에 매핑시킬 실제 번지 값이 되요. 그리고 PointerToRawData의 값은 이 섹션이 위치한 PE 파일 내의 파일 선두로 부터의 오프셋이 되고요.
VirtualAddress 필드와 PointerToRawData 필드는 중요한 필드인 거죠!
아래의 사진은 책에 첨부되더 있는 VirtualAddress와 PointerToRawData 사이의 관계에 대한 그림입니다.
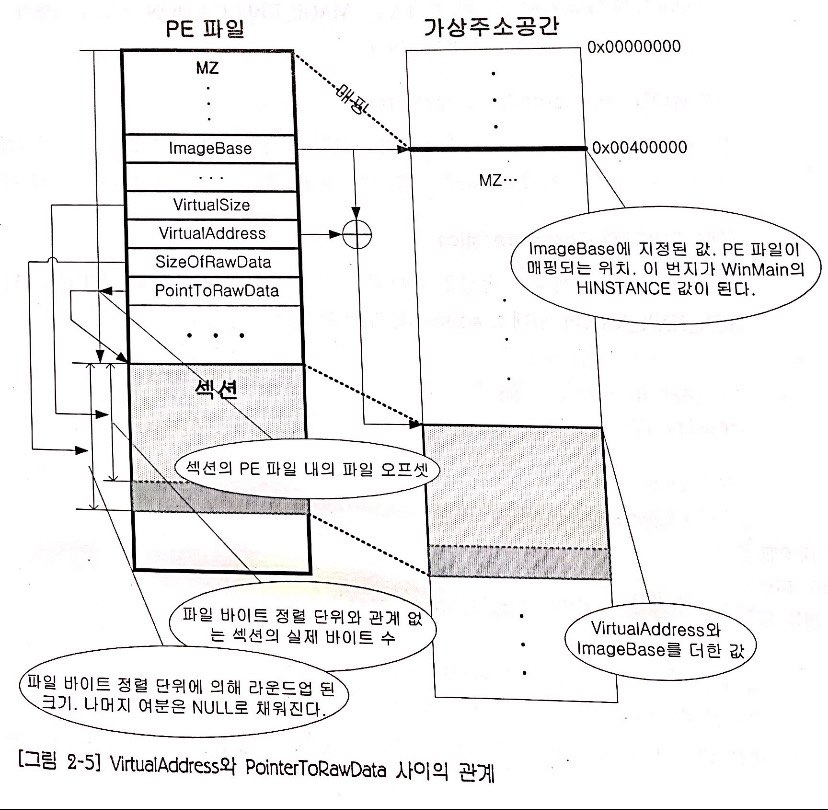
여섯 번째 멤버, PointerToRelocations
본 섹션을 위한 재배치 파일 오프셋이에요. 이 필드는 OBJ에서만 사용되고 실행 파일에서는 0으로 세트되요. OBJ 파일에서 이 필드가 0이 아닐 경우 IMAGE_RELOCATION 구조체 배열의 시작 주소를 가리켜요.
일곱 번째 멤버, PointerToLinenumbers
본 섹션을 위한 COFF 스타일의 라인 번호를 위한 파일 오프셋이에요. 이 필드의 값이 0이 아닐 경우 IMAGE_LINENUMBER 구조체 배열의 시작을 가리키고, COFF 라인 번호가 PE에 첨부되었을 경우에만 사용해요.
여덟 번째 멤버, NumberOfRelocations
PointerToRelocations 필드가 가리키는 IMAGE_RELOCATION 구조체 배열의 원소의 개수에요. 실행 파일에서는 항상 0이에요!
아홉 번째 멤버, NumberOfLinenumbers
PointerToLinenumbers 필드가 가리키는 IMAGE_LINENUMBER 구조체 배열의 원소의 개수에요. 마찬가지로 COFF 라인 번호가 PE 파일에 추가 되어쓸 때만 사용해요.
열 번째 멤버, Characteristics
이 필드는 해당 섹션의 속성을 나타내는 플래그의 집합이에요.
“WinNT.h” 헤더 파일에 IMAGE_SCN_XXX_XXX의 형태로 매크로로 정의되어 있어요.
1 | // Section contains code. |
링커는 링크 시에 필요에 따라서나 혹은 사용자의 지시에 의해 여러 섹션들을 하나로 병합할수 있어요. 병합하는 옵션은 /MERGS:from=to 형식으로 지정하면 되요. 이때 병합된 섹션 내에 특정 섹션이 포함되어 있는지를 확인할 수 있는 플래그 집함을 제공한느데 위의 플래그 집함이 그 목적으로 사용된다고 해요.
IMAGE_SCN_CNT_CODE
섹션의 코드를 포함하고 있고, 보통 이 플래그는 실행 가능 플래그를 의미하는 IMAGE_SCN_MEM_EXECUTE(0x20000000) 플래그와 함께 저장된다고 해요.
IMAGE_SCN_CNT_INITIALIZED_DATA
섹션이 초기화된 데이터를 포함하고 있어요. 실행 가능 섹션과 .bss 섹션을 제외한 거의 대부분의 섹션이 이 플래그를 가져요.
IMAGE_SCN_CNT_UNINTIALIZED_DATA
섹션이 초기화되지 않은 데이터(.bss 섹션 …)들이 가져요.
1 |
위의 매크로 정의들은 메모리 페이지 속성을 나타내는 플래그들이에요.
IMAGE_SCN_MEM_DISCARDABLE
이 섹션은 실행 이미지가 메모리에 완전히 매핑되고 난 뒤 버려질 수 있다는 것을 의미해요.
일단 메모리에 로드(매핑)되고 난 후 프로세스에게 더 이상 의미없는 섹션이며, 가장 일반적인 버릴 수 있는 섹션은 기본 재배치(.reloc)섹션이에요.
IMAGE_SCN_MEM_NOT_CACHD
IMAGE_SCN_MEM_NOT_PAGED
해당 섹션은 페이지되지 않거나 캐쉬되지 않아요. 페이지 되지 않는다는 말은 결코 페이지 파일로 스왑되지 않는 다는 것을 의미하며 이는 항상 RAM에 존재하는 섹션임을 의미해요. 이런 종류의 섹션을 필요로 하는 경우는 커널 모드에서 작동하는 디바이스 드라이버 가능 실행 모듈이에요.
IMAGE_SCN_MEM_SHARED
해당 섹션은 공유 가능한 섹션이라는 것을 의미해요. DLL과 함께 사용될 때 이 섹션에 있는 데이터는 DLL을 사용하는 모든 프로세스들에 의해 공유될 수 있어요.
일반적으로 데이터 섹션들은 공유 불가능하다. 이 말은 해당 DLL을 사용하는 각각의 프로세스는 이 섹션의 데이터에 대한 자신만의 사본을 가진다는 의미에요.
하지만 공유 가능 섹션은 메모리 매니저에게 해당 섹션을 공유 가능하도록 지시해요. 공유 가능 섹션을 만들려면 링커 시에 SHARED 속성을 주면 되요.
LINK /SECTION:MYDATA, RWS …
IMAGE_SCN_MEM_EXECUTE
이 섹션은 실행 가능한 섹션임을 의미해요. 이 플래그는 보통 코드 포함 플래그인 IMAGE_SCN_CNT_CODE 플래그와 함께 셋되요.
IMAGE_SCN_MEM_READ
이 섹션은 읽기 가능한 섹션임을 의미해요. 이 플래그는 언제나 EXE 파일 내의 대부분의 섹션들에 셋되요.
IMAGE_SCN_MEM_WRITE
이 섹션은 쓰기 가능한 섹션임을 의미해요. 이 플래그가 EXE의 섹션에 세트되지 않으면 로더는 메모리 맵드 페이지를 읽기 전용 또는 실행 전용으로 마크한다고 해요.
쓰기 가능한 전형적인 예로 .data와 .bss 섹션이 있고, .idata 섹션 역시 이 플래그를 가져요.
1 | // Section contains comments or some other type of information |
위의 매크로들은 컴파일 후 생성되는 OBJ 파일 내에서만 설정되는 플래그들로서 후에 링크 시에 링크로 하여금 최종 실행 모듈을 생성하는 데 필요한 정보를 참조할 수 있게 되요.
IMAGE_SCN_LNK_INFO
해당 섹션이 링커에 의해 사용될 주석이나 다른 어떤 종류의 정보를 가져요. 이 섹션의 전형적인 예는 컴파일러에 의해 생성되며 링커를 위한 명령을 담고 있는 .drectve 섹션이에요.
IMAGE_SCN_LNK_REMOVE
이 플래그는 링크 시에 최종 실행 파일의 일부가 되지 말아야 할 섹션의 내용들을 지시해요. 이 섹션들은 링커에게 정보를 넘겨주기 위한 컴파일러나 어셈블러에 의해 사용되요.
IMAGE_CSCN_LNK_COMDAT
해당 섹션의 내용은 공용 데이터라는 것을 의미해요. 이것은 COMDATA 라고 하는데, 공용 데이터나 코드 플래그는 여러 OBJ 파일에 걸쳐서 정의될 수 있어요. 링커는 실행 파일로 포함시키기 위해 하나의 복사본을 선택할 수 있어요.
COMDATA는 C++ 템플릿 함수와 함수 레벨 링킹을 지원하는데 매우 중요한 녀석이에요.
1 | // Default alignemnt if no others are sepcifed. |
위의 매크로들은 생성된 실행 파일 내의 해당 섹셔의 데이터 정렬 단위를 나타내는 플래그이며, OBJ 파일 내에서만 셋팅되요.
IMAGE_SCN_ALIGN_XBYTES
_XBYTES의 값으로 1BYT부터 8192BYTE 까지의 정렬 단위를 사타내요. 특별히 지정되지 않으면 디폴트로 16BYTE에 해당하는 IMAGE_SCN_ALIGN_16BYTES가 되고 이 값은 0x00500000 이에요.
마지막으로…
IMAGE_SECTION_HEADER에 있는 멤버들 중, VirtualSize, VirtualAddress, SizeOfRawData, PointerToRawData, Characteristics 멤버에 대해서는 확실하게 알아야 해요.
이 멤버들을 이용해서 메모리의 속성이 어떤지 파악할 수 있고, 어떤 부분이 데이터들이 저장되어 있는지 알 수 있거든요. 이 부분을 알아야지 우리가 필요한 데이터들을 찾을 수 있어요.
PE 파일에서 각 섹션의 실제 내용을 확인하고자 한다면 PointerToRawData가 가리키는 위치로 파일 오프셋을 이동시키고, 그곳에서부터 SizeOfRawData의 바이트 수만큼이 해당 섹션의 실제 내용이 되요.
이 섹션이 실제로 가상 주소 공간에 매핑되었을 때의 RVA가 VirtualAddress가 되며 매핑된 후의 섹션의 실제 시작 포인터를 얻고자 한다면 VirtualAddress 값에다가 IMAGE_OPTIONAL_HEADER의 ImageBase 필드 값을 더하면 되요. 그리고 매핑된 후에 이 섹션이 차지하고 있는 메모리 상의 크기는 VirtualSize에 명시되어 있어요.
일반적으로 포함되어 있는 섹션의 Charateristics 값을 한번 살펴봐요.
.textbss의 속성
- .textbss -> 0xE0000000
- IMAGE_SCN_MEM__EXECUTE -> 0x20000000
- IMAGE_SCN_MEM_READ -> 0x40000000
- IMAGE_SCN_MEM_WRITE -> 0x80000000
- IMAGE_SCN_CNT_CODE -> 0x00000020
- IMAGE_SCN_CNT_UNINITALIZED_DATA -> 0x00000080
.textbss 섹션은 코드 섹션과 초기화되지 않은 데이터가 있는 .bss 섹션이 혼합되어 있다는 것을 알 수 있어요. 그래서 메모리 속성으로는 실행, 읽기, 쓰기 속성이 지정되어 있고, 컨테이터 속성 중에서는 코드 속성과 초기화되지 않는 데이터 속성이 지정되어 있죠.
.text의 속성
- .text -> 0x60000020
- IMAGE_SCN_MEM_EXECUTE -> 0x20000000
- IMAGE_SCN_MEM_READ -> 0x40000000
- IMAGE_SCN_CNT_CODE -> 0x00000020
이 섹션은 코드 섹션으로서 전형적인 콛그 섹션의 속성만을 가지고 있어요. 메모리 속성으로는 실행과 읽기 속성을 가지며 컨테이너 속성으로는 코드 속성을 가져요.
.rdata의 속성
- .rdata -> 0x40000040
- IMAGE_SCN_MEM_READ -> 0x40000000
- IMAGE_SCN_CNT_INITIALIZED_DATA -> 0x00000040
이 섹션은 읽기 전용 데이터 섹션이에요. 따라서 메모리 속성은 읽기 속성만 가지며 컨테이너 속성으로는 초기화된 데이터 속성을 가져요.
.data, .idata의 속성
- .data, .idata -> 0xC0000040
- IMAGE_SCN_MEM_READ -> 0x40000000
- IMAGE_SCN_MEM_WRITE -> 0x80000000
- IMAGE_SCN_CNT_INITIALIZED_DATA -> 0x00000040
.data 섹션은 전형적인 데이터 섹션이에요. 그래서 읽기 쓰기가 가능하며, 초기화된 전역 변수들은 모두 이 섹션에 자리를 잡아요. 따라서 메모리 속성은 읽기, 쓰기 속성이 모두 지정되어 있으며 컨테이너 속성은 초기화된 데이터 속성이에요.
.idata 섹션은 임포트된 DLL과 그 함수들에 대한 정보를 담고 있는 섹션이에요. 따라서 프로그램 로드 시에 로더는 이 섹션을 참조하여 해당 DLL을 메모리에 매핑을 시켜요. 그렇기 때문에 당연히 메모리 속성은 읽기 속성을 가져야 해요. 그리고 이 정보는 링크 시에 정해지기 때문에 초기화된 데이터 컨테이너 속성을 가질 수밖에 없어요.
하지만 임포트 섹션은 왜 쓰기 속성을 가질까요? 그 이유는 로더가 DLL을 로드한 후에 이 섹션에 존재하는 DLL에 속하는 임포트 함수에 대한 함수 포인터를 임포트 주소 테이블(IAT)라고 하는 곳에 저장하기 떄문이에요.
임포트 주소 테이블(IAT)이 임포트 섹션 내에 존재하기 때문에 임포트 섹션은 쓰기 속성을 가져야만 하고, 임포트 함수를 사용할 때 임포트 주소 테이블(IAT)를 통해서 함수의 포인터를 얻어서 사용해요.




